
A Kafka streaming application with Quarkus
![]()
The Kafka streaming application platform is becoming “de facto” the modern approach to the ETL (Extract, transform and load) world. Probably you already read a lot about “What is Kafka”, “What is a topic” and “What is a partition”, but i want to discuss with you “What is a streaming application”, this is the aim of this article, I hope I’ll achieve the goal. The book “Kafka streams in Action” defines the stream processing as “working with data as it’s arriving in your system” or more refined “stream processing is the ability to work with an infinite stream of data with continuous computation, as it flows, with no need to collect or store the data to act on it”. Usually, we use a stream processing application when we have a lot of data (BigData) and the need to quickly respond to or report on incoming data.
Before continuing, the complete example described here, it’s published on Github at https://github.com/paspao/quarkus-streaming-app, it doesn’t contain the streaming app only, but a complete deployment scenarios:
- 1 Zookeeper instance
- 3 Kafka instances
- 1 Kafdrop instance (easy way to give a look inside the Kafka topic/instance etc)
- 1 Streaming app (described in this article)
Through Kafdrop you can verify the content the Kafka topics.
Now, let’s suppose that all the data are already present inside Kafka topics, i tried to draw them in the below picture:

So i have created four simple entities (each one is a Kafka topic representation): Person, DriverLicense, Sim, Fee. The data architecture is pretty simple: a person could have some driver licenses, a person could have sim cards and last but not least a person pays the fees unfortunately. I marked with red color the key of the topics and the entire row is the kafka message or the payload.
Obviously, the table representation is a simplification, we have to keep in mind that each row in the table could be more than one message, like in the picture below:

We could have multiple versions of the same row/message, why?

Kafka acts like a commit log which is a record of transactions. In a database context, it’s used to keep track of what’s happening, and it helps with disaster recovery, it represents the bearing structure of all RDBMS. We can define that a commit log is an immutable, ordered record of events.
Well, Kafka stores two hidden values for each row: an offset and a timestamp. With the offset field you can univocal identify a row in a partition. The choice to manage these two hidden values is due to manage the time: indeed Kafka gives us the option to process the messages in a specific time window. For example we could decide to process the messages that we received in the year 2009, ignoring all the messages that we have received before or after that year, ignoring it is what allow us to achieve high speed, in fact this is one of the secrets for realtime processing (streaming) sponsored/achieved by Kafka.
Now come back to the example. My first goal is to join two simple topic that are Person and DriverLicense because i want to discover how many person already had a driver license, so let’s start to join these two topics. From a data perspective to join two topics they have to respect the co-partitioning requirements that are:
- The input records for the join must have the same key (or key schema)
- The input records must have the same number of partitions on both sides
- Both sides of the join must have the same partitioning strategy (usually we use the default one offered by the Kafka client, practically ignoring the ability to choose a different one)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public Topology appJoinPersonAndDriverLicense() {
final KStream<String, Person> personStream = builder.stream(PERSON,
Consumed.with(Serdes.String(), FactorySerde.getPersonSerde()));
final KStream<String, DriverLicense> driverLicenseStream = builder.stream(DRIVERLICENSE,
Consumed.with(Serdes.String(), FactorySerde.getDriverLicenseSerde()));
KStream<String, Person> peekStream = personStream.peek(loggingForEach);
KStream<String, PersonDriverLicense> joined = peekStream.join(driverLicenseStream,
(person, license) -> new PersonDriverLicense(person, license),
JoinWindows.of(Duration.of(5, ChronoUnit.MINUTES)), StreamJoined.with(
Serdes.String(), /* key */
FactorySerde.getPersonSerde(), /* left value */
FactorySerde.getDriverLicenseSerde() /* right value */
));
joined.to(ALL, Produced.with(Serdes.String(), FactorySerde.getPersonDriverLicenseSerde()));
Topology build = builder.build();
logger.info(build.describe().toString());
return build;
}
final ForeachAction<String, Person> loggingForEach = (key, person) -> {
if (person != null)
logger.info("Key: {}, Value: {}", key, person);
};
In this code snippet you don’t find the configuration, this is not our focus, here the focus is the streaming (you can find the details in the repo anyway): at lines 3 and 5 we defined two streams one for the Person topic and one for the DriverLicense topic, then just a peek operation to log the stream person and later the join operation at lines 10-16 between Person and DriverLicense. Be careful, I used a peekStream and not the personStream at line 10 because I wanted to add a new node in order to log the flow (I’m building a topology…), we need something to see this topology, so at line 21 I printed out the stream/topology in the console log, it’s a logical description:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [person])
--> KSTREAM-PEEK-0000000002
Processor: KSTREAM-PEEK-0000000002 (stores: [])
--> KSTREAM-WINDOWED-0000000003
<-- KSTREAM-SOURCE-0000000000
Source: KSTREAM-SOURCE-0000000001 (topics: [driverlicense])
--> KSTREAM-WINDOWED-0000000004
Processor: KSTREAM-WINDOWED-0000000003 (stores: [KSTREAM-JOINTHIS-0000000005-store])
--> KSTREAM-JOINTHIS-0000000005
<-- KSTREAM-PEEK-0000000002
Processor: KSTREAM-WINDOWED-0000000004 (stores: [KSTREAM-JOINOTHER-0000000006-store])
--> KSTREAM-JOINOTHER-0000000006
<-- KSTREAM-SOURCE-0000000001
Processor: KSTREAM-JOINOTHER-0000000006 (stores: [KSTREAM-JOINTHIS-0000000005-store])
--> KSTREAM-MERGE-0000000007
<-- KSTREAM-WINDOWED-0000000004
Processor: KSTREAM-JOINTHIS-0000000005 (stores: [KSTREAM-JOINOTHER-0000000006-store])
--> KSTREAM-MERGE-0000000007
<-- KSTREAM-WINDOWED-0000000003
Processor: KSTREAM-MERGE-0000000007 (stores: [])
--> KSTREAM-SINK-0000000008
<-- KSTREAM-JOINTHIS-0000000005, KSTREAM-JOINOTHER-0000000006
Sink: KSTREAM-SINK-0000000008 (topic: alltogether)
<-- KSTREAM-MERGE-0000000007We can use this snippet to draw the topology using a tool like https://zz85.github.io/kafka-streams-viz/, below you can find the result:
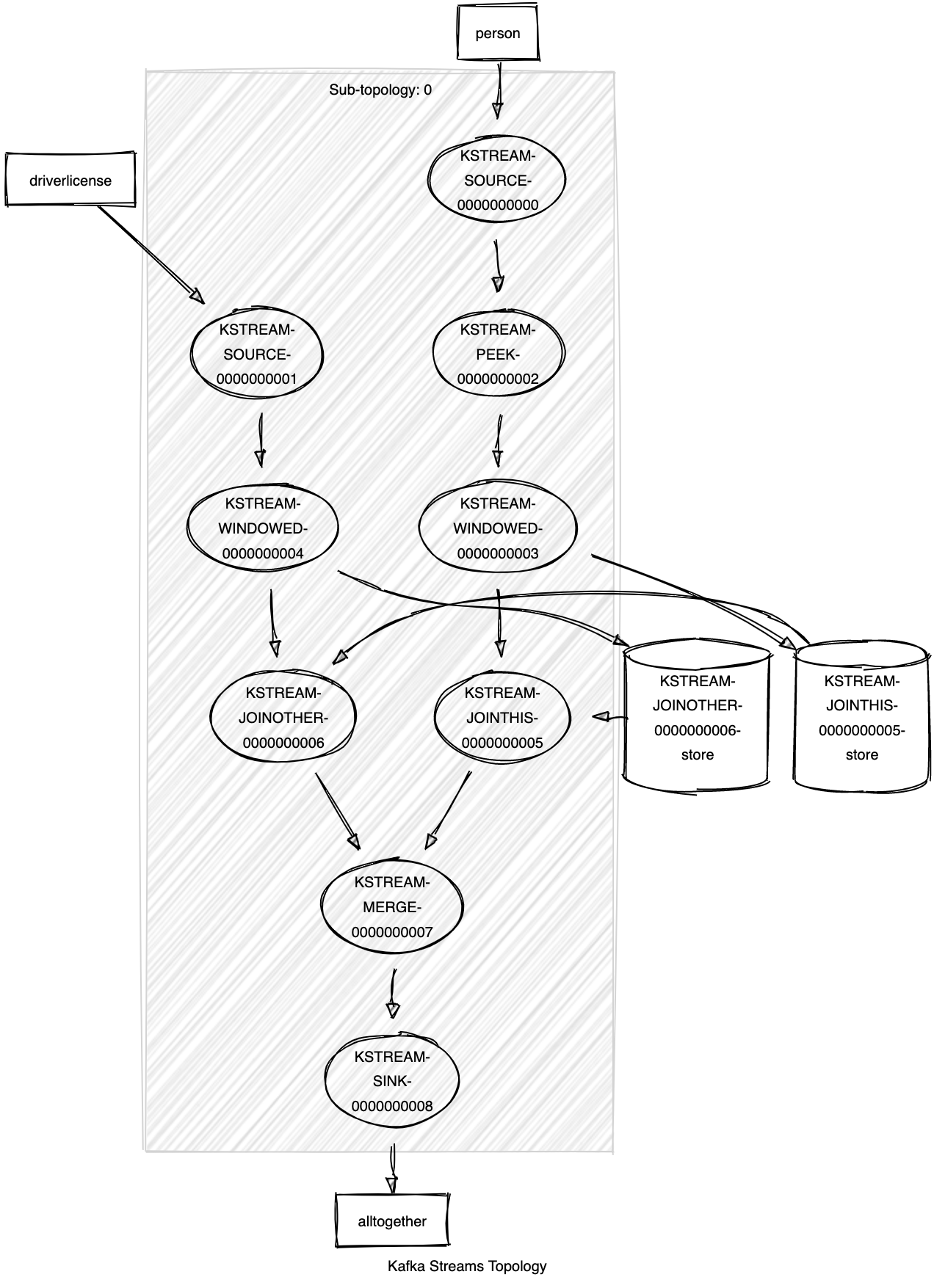
Well, now we have a graphical representation of our simple topology. It’s more clear to see the topics, the stream and the peek operation we already discussed, but now we can see more clearly what happen during a join operation. At line 12 we used a JoinWindow, the join operation is a stateful transformation, we need a state store to collect all of the records received so far within the defined window boundary. With Kafka we have the ability to consider the time as data, so we don’t want to process all the updates received a for a specific record but only what is changed in the last 5 minutes for example, in this way I will process only few kilobyte of data (in a BigData context we could have topic with Terabyte of data). So, topology wise for each element of the join operation a state store will be created (the two cylinder on the right side of the picture) and a corresponding topic will be created on Kafka as well, these topics are named as store-changelog topics, this to ensure the the foult-talerant capabilities of the Kafka Streams. As described in the Confluent documentation: “These changelog topics are partitioned as well so that each local state store instance, and hence the task accessing the store, has its own dedicated changelog topic partition. Log compaction is enabled on the changelog topics so that old data can be purged safely to prevent the topics from growing indefinitely. If tasks run on a machine that fails and are restarted on another machine, Kafka Streams guarantees to restore their associated state stores to the content before the failure by replaying the corresponding changelog topics prior to resuming the processing on the newly started tasks. As a result, failure handling is completely transparent to the end user.”
So, in the final step at line 18 the data will be joined by the key and the result will be stored in the alltogether topic, something like:
{
"person": {
"ssn": "789",
"name": "Giacchino",
"surname": "Murat",
"sex": "M",
"dateOfBirth": "1981-06-28",
"phoneNumber": "1113245798"
},
"driverLicense": {
"id": "789",
"type": "CAR",
"licenseNumber": "4213245768"
}
}Well, now let’s try to create a more complex/realistic scenario: let’s try to join topics not co-partitionated or at least not yet, so what we will try to do now is joining the alltogether topic with the fee topic . The result will be a payload with:
- Person
- Driver License
- Fee
The first part is already implemented (it’s a copy of the previous one) so we can completly ignore the lines 1-20:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
public Topology appJoinPersonAndDriverLicenseAndFee() {
final KStream<String, Person> personStream = builder.stream(PERSON,
Consumed.with(Serdes.String(), FactorySerde.getPersonSerde()));
final KStream<String, DriverLicense> driverLicenseStream = builder.stream(DRIVERLICENSE,
Consumed.with(Serdes.String(), FactorySerde.getDriverLicenseSerde()));
KStream<String, Person> peekStream = personStream.peek(loggingForEach);
KStream<String, PersonDriverLicense> joinedPersonDriverLicense = peekStream.join(driverLicenseStream,
(person, license) -> new PersonDriverLicense(person, license),
JoinWindows.of(Duration.of(5, ChronoUnit.MINUTES)), StreamJoined.with(
Serdes.String(), /* key */
FactorySerde.getPersonSerde(), /* left value */
FactorySerde.getDriverLicenseSerde() /* right value */
));
joinedPersonDriverLicense.to(ALL, Produced.with(Serdes.String(), FactorySerde.getPersonDriverLicenseSerde()));
// End of the first example
final KStream<String, Fee> feeStream = builder.stream(FEE,
Consumed.with(Serdes.String(), FactorySerde.getFeeSerde()));
KeyValueBytesStoreSupplier feeBySsnTableSupplier = Stores.persistentKeyValueStore("feeBySsnTableSupplier");
final Materialized<String, FeeBySsn, KeyValueStore<Bytes, byte[]>> materialized =
Materialized.<String, FeeBySsn>as(feeBySsnTableSupplier)
.withKeySerde(Serdes.String())
.withValueSerde(FactorySerde.getFeeBySsnSerde());
KStream<String, PersonDriverLicenseFee> joinedPersonDriverLicenseFee = feeStream
.selectKey((key, value) -> value.getSsn())
.groupByKey(Grouped.with(Serdes.String(), FactorySerde.getFeeSerde()))
.aggregate(() -> new FeeBySsn(), (key, value, aggregate) -> {
aggregate.setSsn(key);
aggregate.getFeeList().add(value);
return aggregate;
}, materialized)
.toStream()
.join(joinedPersonDriverLicense,
(feeBySsn, personDl) -> new PersonDriverLicenseFee(personDl.getPerson(), personDl.getDriverLicense(), feeBySsn),
JoinWindows.of(Duration.of(5, ChronoUnit.MINUTES)), StreamJoined.with(
Serdes.String(), /* key */
FactorySerde.getFeeBySsnSerde(), /* left value */
FactorySerde.getPersonDriverLicenseSerde() /* right value */
));
joinedPersonDriverLicenseFee.to(ALL_ENHANCEMENT, Produced.with(Serdes.String(), FactorySerde.getPersonDriverLicenseFeeSerde()));
Topology build = builder.build();
logger.info(build.describe().toString());
return build;
}
final ForeachAction<String, Person> loggingForEach = (key, person) -> {
if (person != null)
logger.info("Key: {}, Value: {}", key, person);
};
At line 24 we defined a new stream for the fee topic, then at lines 27-32 we defined something of new that is a persistent KeyValue store used to set the serde classes that are used to serialize and deserialize the data.
At line 34 we start to join alltogether topic with fee topic:
- we need to “override” the key of the fee topic as i cannot join two topics with different keys, we do it at line 35
- when overriding the key you need to define an aggregation strategy as well, it’s done at lines 37-41.
- now the fee stream is ready to join with alltogether so at lines 42-49 we simply join these two streams defining the serialization and the time window (in our example the time window is just an example)
- last step the joined data are moved to a new topic
As usual at line 53 we print out the description of the defined topology:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [person])
--> KSTREAM-PEEK-0000000003
Processor: KSTREAM-PEEK-0000000003 (stores: [])
--> KSTREAM-WINDOWED-0000000004
<-- KSTREAM-SOURCE-0000000000
Source: KSTREAM-SOURCE-0000000001 (topics: [driverlicense])
--> KSTREAM-WINDOWED-0000000005
Processor: KSTREAM-WINDOWED-0000000004 (stores: [KSTREAM-JOINTHIS-0000000006-store])
--> KSTREAM-JOINTHIS-0000000006
<-- KSTREAM-PEEK-0000000003
Processor: KSTREAM-WINDOWED-0000000005 (stores: [KSTREAM-JOINOTHER-0000000007-store])
--> KSTREAM-JOINOTHER-0000000007
<-- KSTREAM-SOURCE-0000000001
Processor: KSTREAM-JOINOTHER-0000000007 (stores: [KSTREAM-JOINTHIS-0000000006-store])
--> KSTREAM-MERGE-0000000008
<-- KSTREAM-WINDOWED-0000000005
Processor: KSTREAM-JOINTHIS-0000000006 (stores: [KSTREAM-JOINOTHER-0000000007-store])
--> KSTREAM-MERGE-0000000008
<-- KSTREAM-WINDOWED-0000000004
Source: feeBySsnTableSupplier-repartition-source (topics: [feeBySsnTableSupplier-repartition])
--> KSTREAM-AGGREGATE-0000000011
Processor: KSTREAM-AGGREGATE-0000000011 (stores: [feeBySsnTableSupplier])
--> KTABLE-TOSTREAM-0000000015
<-- feeBySsnTableSupplier-repartition-source
Processor: KSTREAM-MERGE-0000000008 (stores: [])
--> KSTREAM-WINDOWED-0000000017, KSTREAM-SINK-0000000009
<-- KSTREAM-JOINTHIS-0000000006, KSTREAM-JOINOTHER-0000000007
Processor: KTABLE-TOSTREAM-0000000015 (stores: [])
--> KSTREAM-WINDOWED-0000000016
<-- KSTREAM-AGGREGATE-0000000011
Processor: KSTREAM-WINDOWED-0000000016 (stores: [KSTREAM-JOINTHIS-0000000018-store])
--> KSTREAM-JOINTHIS-0000000018
<-- KTABLE-TOSTREAM-0000000015
Processor: KSTREAM-WINDOWED-0000000017 (stores: [KSTREAM-JOINOTHER-0000000019-store])
--> KSTREAM-JOINOTHER-0000000019
<-- KSTREAM-MERGE-0000000008
Processor: KSTREAM-JOINOTHER-0000000019 (stores: [KSTREAM-JOINTHIS-0000000018-store])
--> KSTREAM-MERGE-0000000020
<-- KSTREAM-WINDOWED-0000000017
Processor: KSTREAM-JOINTHIS-0000000018 (stores: [KSTREAM-JOINOTHER-0000000019-store])
--> KSTREAM-MERGE-0000000020
<-- KSTREAM-WINDOWED-0000000016
Processor: KSTREAM-MERGE-0000000020 (stores: [])
--> KSTREAM-SINK-0000000021
<-- KSTREAM-JOINTHIS-0000000018, KSTREAM-JOINOTHER-0000000019
Sink: KSTREAM-SINK-0000000009 (topic: alltogether)
<-- KSTREAM-MERGE-0000000008
Sink: KSTREAM-SINK-0000000021 (topic: alltogether-enhancement)
<-- KSTREAM-MERGE-0000000020
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000002 (topics: [fee])
--> KSTREAM-KEY-SELECT-0000000010
Processor: KSTREAM-KEY-SELECT-0000000010 (stores: [])
--> feeBySsnTableSupplier-repartition-filter
<-- KSTREAM-SOURCE-0000000002
Processor: feeBySsnTableSupplier-repartition-filter (stores: [])
--> feeBySsnTableSupplier-repartition-sink
<-- KSTREAM-KEY-SELECT-0000000010
Sink: feeBySsnTableSupplier-repartition-sink (topic: feeBySsnTableSupplier-repartition)
<-- feeBySsnTableSupplier-repartition-filterIt’s really more complex now, below the graphical representation of the snippet above:
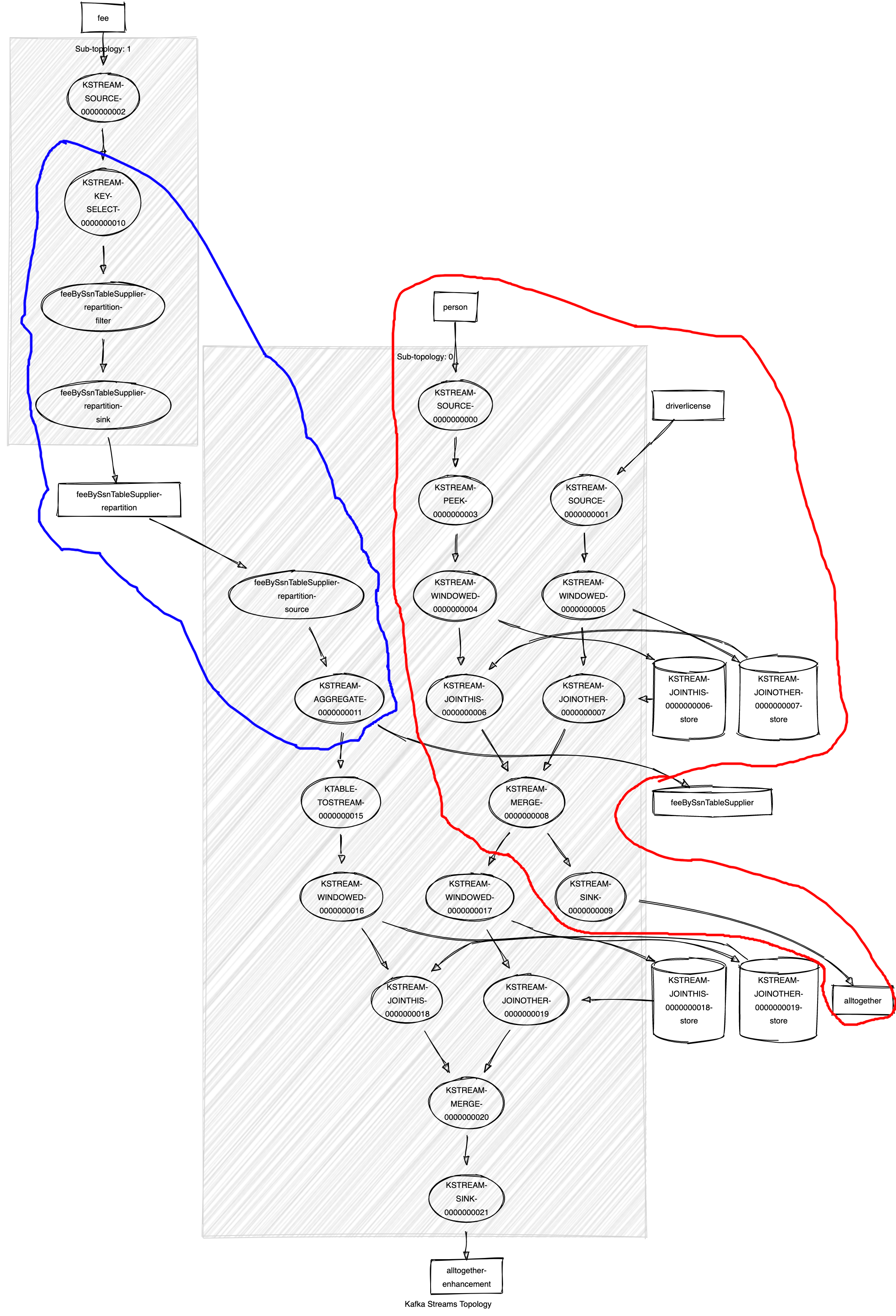
I highlighted with the red line the first topology analyzed in the first section of the article, it’s just represented differently by the graph tool, everything outside the red section was added by the second topology. With the blue section I highlighted the select key/repartition operation needed to respect the co-partition rule. The result of this new join topology is shown below:
{
"person": {
"ssn": "456",
"name": "Pasquale",
"surname": "Paola",
"sex": "M",
"dateOfBirth": "1981-06-25",
"phoneNumber": "1113245768"
},
"driverLicense": {
"id": "456",
"type": "MOTORBIKE, CAR",
"licenseNumber": "1213245768"
},
"feeBySsn": {
"ssn": "456",
"feeList": [
{
"id": "456",
"ssn": "456",
"name": "TASI",
"value": 515
},
{
"id": "123",
"ssn": "456",
"name": "IMU",
"value": 512
},
{
"id": "567",
"ssn": "456",
"name": "IMU",
"value": 516
}
]
}
}Thank you a lot for reading and let me know if something it’s not clear.